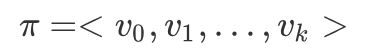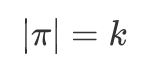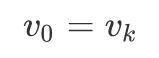清华大学 邓俊辉 《数据结构》 学习笔记
概述 基本术语 G = (V; E)
vertex: n = |V|
edge|arc: e = |E|
邻接和关联 adjacency 邻接关系 顶点与顶点
incidence 关联关系 顶点与其相关的边
树结构可以视为图的一种特殊形式
有向和无向 若邻接顶点 u 和 v 的次序无所谓,则 (u, v) 为无向边,所有边均无方向的图为为无向图
有向图中均为有向边,u、v分别称作边 (u, v) 的尾、头
含有有向边和无向边的图为混合图
可以将无向边转化为彼此对称的一对有向边。
路径和环路 路径:
长度:
简单路径:不含重复节点的路径
简单环路:不包含重复节点的环路
在一个有向图中不包含任何环路,称之为有向无环图 (DAG)
欧拉环路(Eulerian tour ):经过所有的边且恰好一次的环路
哈密尔顿环路(Hamiltonian tour):恰好经过每个顶点一次的环路
邻接矩阵 接口 定义 Graph 模板类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 template <typename Tv, typename Te> class Graph //顶点类型,边类型{ private : void reset () { for (int i = 0 ; i < n; i++) { status(i) = UNDISCOVERED; dTime(i) = fTime(i) = -1 ; parent(i) = -1 ; priority(i) = INT_MAX; for (int j = 0 ; j < n; j++) { if (exisits(i,j)) status(i,j) = UNDETERMINED; } } } public : }
邻接矩阵与关联矩阵 邻接矩阵:描述顶点相互邻接关系的矩阵
n 行 n 列,矩阵中第 i 行与第 j 列的元素表示顶点 i 和顶点 j 是否存在一条边。无向图则为对称矩阵。若为带权图,可以将权重存入矩阵
关联矩阵
n 行 e 列,存在关联关系,记作 1,否则记作 0,对于矩阵中任意一列,应该恰好只有两个单元的数值为1
默认值放在左上角
顶点和边 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 typedef enum { UNDISCOVERED, DISCOVERED, VISITED } VStatus;template <typename Tv> struct Vertex //顶点对象(并未严格封装){ Tv data; int inDegree, outDegree; Vstatus status; int dTime, fTime; int parent; int priority; Vertex( Tv const & d) : data(d), inDegree(0 ), outDegree(0 ), status(UNDISCOVERED), dTime(-1 ), fTime(-1 ), parent(-1 ), priority(INT_MAX) {} } typedef enum {UNDETERMINED, TREE, DROSS, FORWARD, BACKWARD} EStatus;template <typename Te> struct Edge //边对象(并未严格封装){ Te data; int weight; EStatus status; Edge (Te const & d, int w): data(d), weight(w), status(UNDETERMINED){} }
邻接矩阵 GraphMatrix 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <typename Tv, typename Te> class GraphMatrix :public Graph <Tv, Te>{ private : Vector < Vertex<Tv> > V; Vector < Vector< Edge<Te>* > > E; public : GraphMatrix() { n = e = 0 ;} ~GraphMatrix() { for (int j = 0 ; j < n; j++) for (int k = 0 ; k < n; k++) delete E[j][k] } };
顶点操作 1 2 3 4 5 6 7 8 Tv & vertex (int i) {return V[i].data;} int inDegree (int i) return V[i].inDegree;} int outDegree (int i) return V[i].outDegree;} Vstatus & stauts (int i) {return V[i].status;} int & dTime (int i) return V[i].dTime;} int & fTime (int i) return V[i].ftime;} int & parent (int i) return V[i].parent;} int & priority (int i) return V[i].priority;}
对于任意顶点 i,枚举其所有的邻接顶点 neighbour
1 2 3 4 5 6 7 8 9 int nextNbr (int i, int j) while ((-1 <j) && !exists(i,--j)); return j; } int firstNbr (int i) nextNbr(i,n); }
边操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 bool exists (int i, int j) return (0 <= i) && (i < n) && (0 <= j) && (j < n) && e[i][j]!=NULL ; } Te & edge (int i, int j) return e[i][j]->data; } Estatus & status (int i, int j) return e[i][j]->status; } int & weight (int i, int j) return E[i][j]->weight; }
边插入 将边 (i,j) 封装为一个新的边记录,将其地址存入邻接矩阵
1 2 3 4 5 6 7 8 void insert (Te const & edge, int w, int i, int j) if (exists(i,j)) return ; e[i][j] = new Edge<Te>(edge,w); e++; V[i].outDegree++; V[j].inDegree++; }
边删除 将矩阵中对应边的记录释放,指针置为空
1 2 3 4 5 6 7 8 9 Te remove (int i, int j) Te eBak = edge(i, j); delete E[i][j]; E[i][j] = NULL ; e--; V[i].outDegree--; V[j].outDegree--; return eBak; }
顶点动态操作 增加顶点 1 2 3 4 5 6 7 8 9 int insert (Tv const & vertex) for (int j = 0 ; j < n; j++) E[j].insert(NULL ); n++; E.insert(Vector < Edge<Te>* > (n, n, NULL )); return V.insert(Vertex<Tv>(vertex)); }
删除顶点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Tv remove (int i) for (int j = 0 ; j < n; j++) if (exists(i, j)) { delete E[i][j]; V[j].inDegree--; } E.remove(i); n--; for (int j = 0 ; j < n; j++) if (exists(j,i)) { delete E[j].remove(i); V[j].outDegree--; } Tv vBak = vertex(i); V.remove(i); return vBak; }
广度优先搜索 思路:化繁为简
自始顶点 s 的广度优先搜索(Breadth-First_Search)
访问顶点 s
依次访问 s 所有尚未访问 的邻接顶点
依次访问它们尚未访问 的邻接顶点
…
如此反复,直至没有尚未访问 的邻接顶点
可视为树的层次遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 template <typename Tv, typename Te> void Graph<Tv, Te>::BFS(int v, int & clock){ Queue<int > Q; status(v) = DISCOVERED; Q.enqueue(v); while (!Q.empty()) { int v = Q.dequeue(); dTime(v) = ++clock; for (int u = firstNbr(v); -1 < u; u = nextNbr(v, u)) { if (UNDISCOVERED == status(u)) { status (u) = DISCOVERED; Q.enqueue u; status (v,u) = TREE; parent(u) = v; } else { status(u, v) = CROSS; } } status(v) = VISITED; } }
多连通 1 2 3 4 5 6 7 8 9 10 11 template <typename Tv, typename Te> void Graph<Tv, Te>::bfs(int s) { reset(); int clock = 0 ; int v = s; do { if (UNDISCOVERED == status(v)) BFS (v, clock); }while (s != (v = (++v % n))); }
Graph::DFS
外部:while循环执行O(n)
内部:for循环本身 n*n 内层循环实际操作e次
理论上渐进 O(n^2) ,实际中远远不是这样。连续、规则、紧凑的组织形式利于高速缓冲机制发挥作用,存储级别之间巨大的速度差异在实际应用中往往更为举足轻重。因此,实际中可以将n忽略掉,近似为 O(n+e),若使用邻接表,则为 O(n+e)
深度优先搜索 DFS(s):始自顶点 s 的深度优先搜索
访问顶点 s
若 s 尚有未被访问的邻居,则任取其一 u,递归执行 DFS(u)
否则,返回
得到一颗DFS树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 template <typename Tv, typename Te> void Graph<Tv, Te>::DFS(int v, int & clock){ dTime(v) = ++clocl; status(v) = DISCOVERED; for (int u = firstNbr(v); -1 < u; u = nextNbr(v,u)) { switch (status(u)) { case UNDISCOVERED: status(v, u) = TREE; parent(u) = v; DFS(u, clock); break ; case DISCOVERED: status(v, u) = BACKWROD; break ; default : status(v, u) = dTime(v) < dTime(u) ? FORWARD : CROSS; break ; } } status(v) = VISITED; fTime(v) = ++clock; }
多可达域 类似 BFS 的处理方法,在外层添加循环
括号引理/嵌套引理 顶点的活动期:active[u] = (dTime[u], fTime[u])
Parenthesis Lemm:给定有向图 G = (V, E) 及其任一 DFS 森林,则
u 是 v 的后代 iff active[u]为 active[v] 的子集
u 是 v 的祖先 iff active[u] 为 active[v] 的子集
u 与 v 无关 iff active[u] 与 active[v] 的交际为空集